
Jingyi Chen
About Me
I am a Ph.D. Candidate in Computational Linguistics at The Ohio State University, specializing in speech synthesis, multimodal large language models, and reinforcement learning for audio. I work under the supervision of Dr. Micha Elsner and Dr. Andrew Perrault, with committee members Dr. Eric Fosler-Lussier and Dr. Cynthia Clopper. My research focuses on advancing speech synthesis through reinforcement learning and diffusion models, developing speech emotion conversion systems, and creating benchmarks for evaluating multimodal LLMs on emotional speech understanding.
Previously, I completed my M.S. in Computer Science & Engineering at OSU. I have industry experience as an Applied Scientist Intern at Amazon, including at Amazon DEX AI (Summer 2025), where I built LLM-based ranking systems for product recommendations, and at Amazon Prime Video (Summer 2024), where I developed production-ready speech emotion transfer systems.
Research Interests
- Speech Synthesis: Text-to-speech systems, diffusion models, emotional speech generation, GANs for speech representation learning
- Multimodal Large Language Models: Speech-text cooperation, instruction tuning, semantic-emotion disentanglement
- Reinforcement Learning for Audio: RLHF, reward-based optimization, model fine-tuning
News
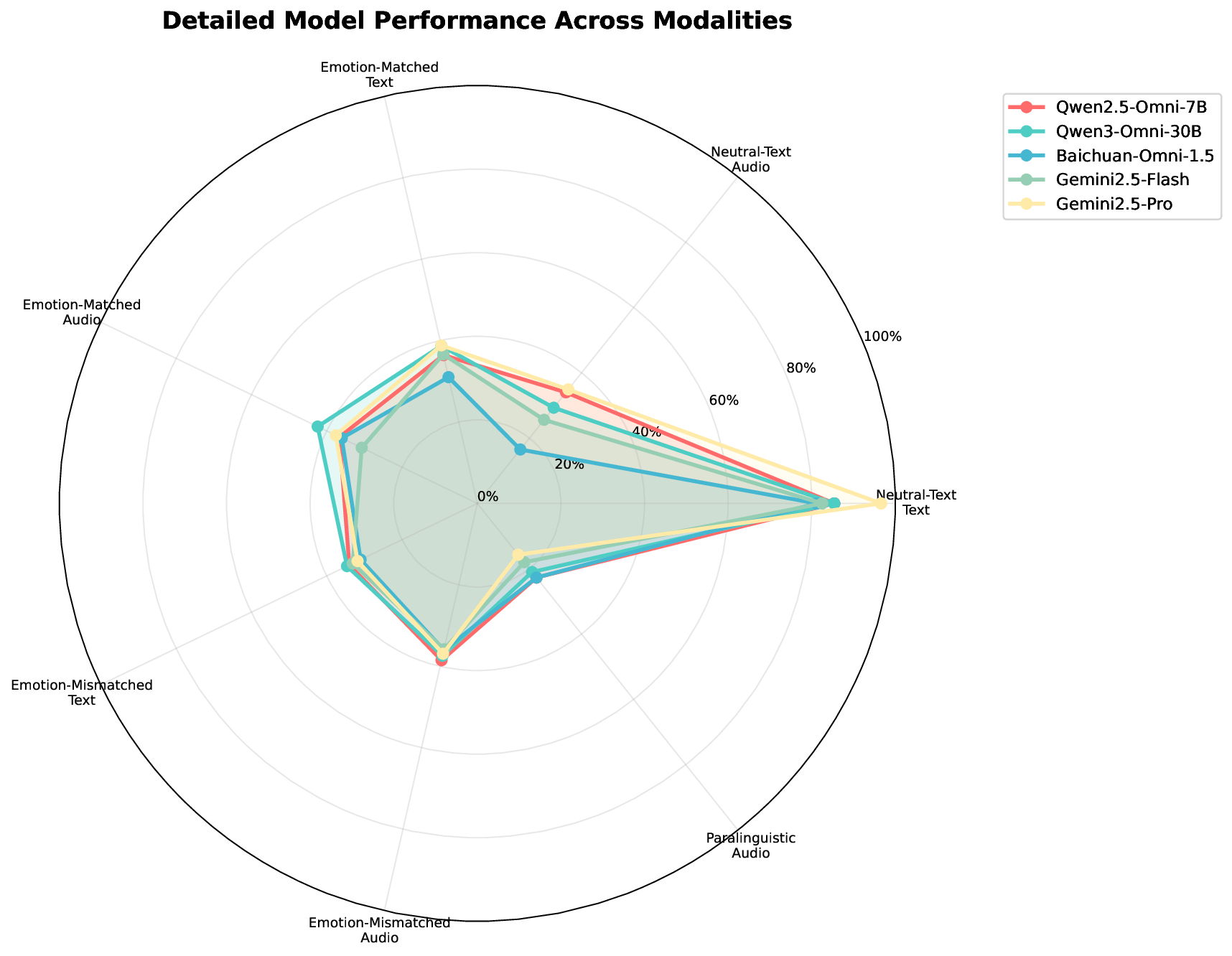
- [Early 2026] Paper “Do Audio LLMs Really LISTEN, or Just Transcribe?” accepted to EACL 2026.
- [Oct. 2025] Released LISTEN benchmark for evaluating lexical vs. acoustic cue reliance in audio LLMs.
- [Aug. 2025] Completed internship at Amazon DEX AI, where I built LLM-based ranking systems for low-consideration purchases.
- [Aug. 2025] Started new research project on Social-Emotional Speech Dialogue Benchmark for Multimodal LLMs.
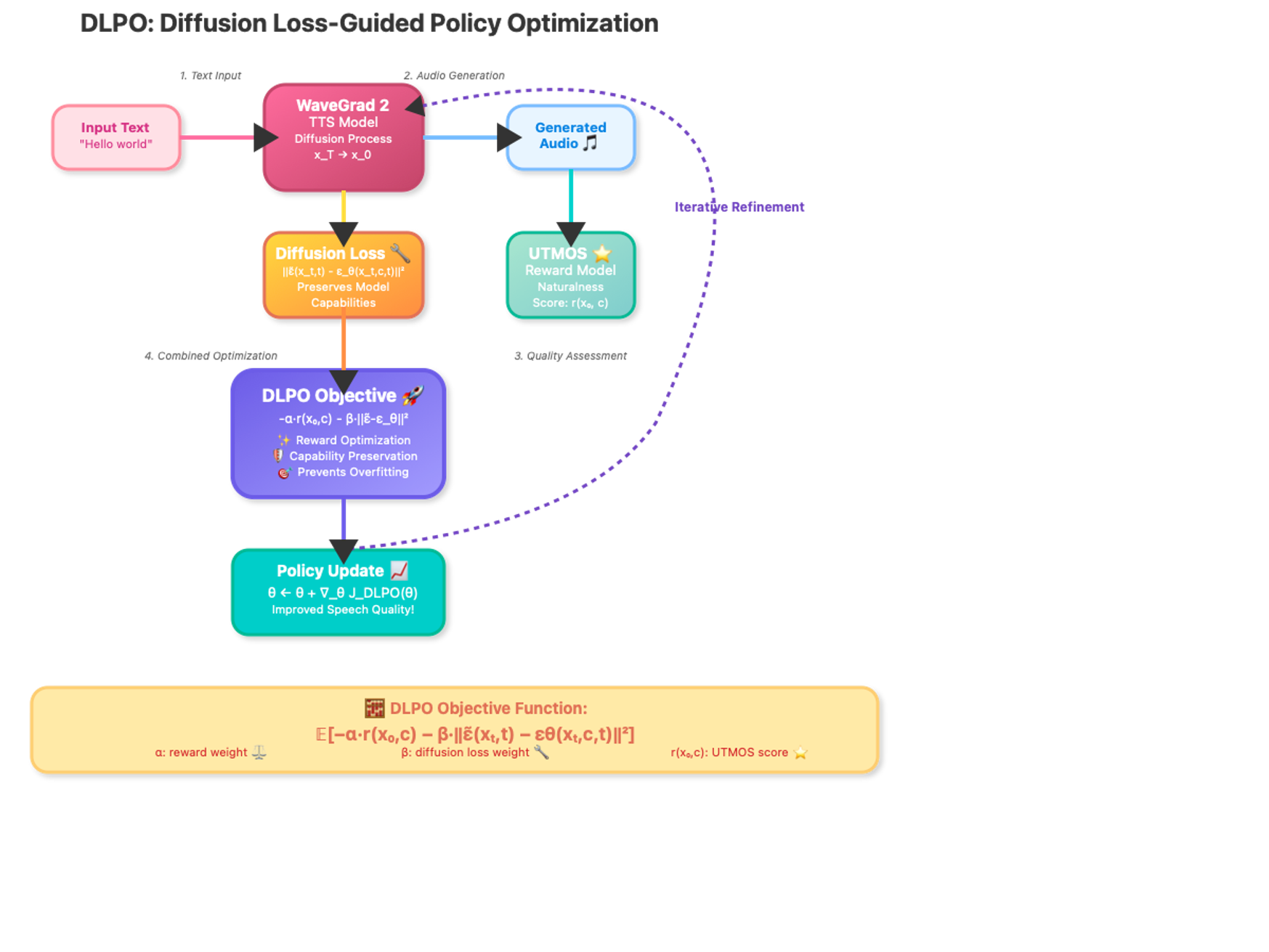
- [May 2025] Paper “Reinforcement Learning for Fine-tuning Text-to-speech Diffusion Models” accepted to Interspeech 2025 (Oral Presentation).
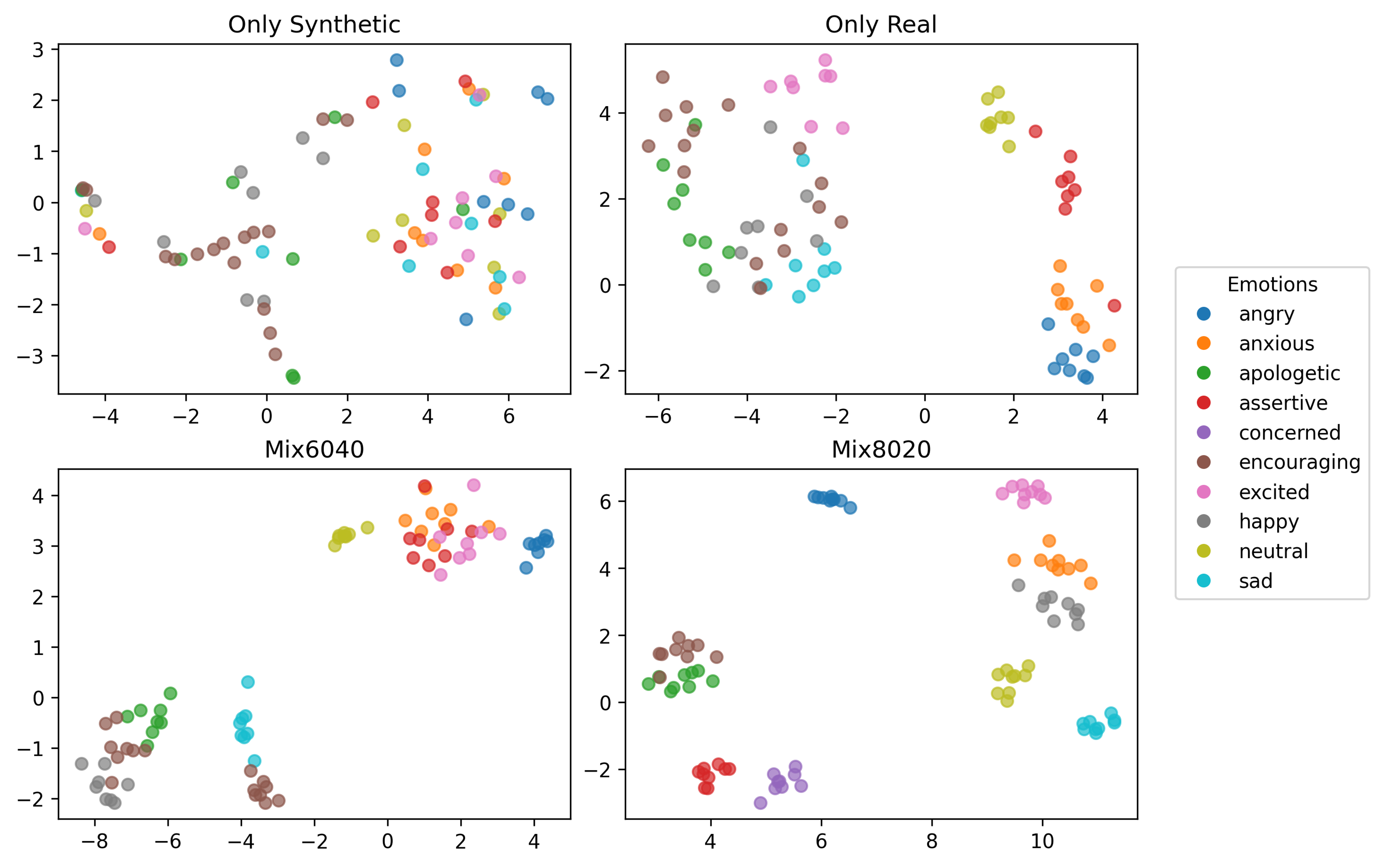
- [Jan. 2025] Released comprehensive emotion transfer dataset with 27K audio samples and published project page.
- [Aug. 2024] Completed internship at Amazon Prime Video, delivered speech-to-speech emotion transfer model to production.
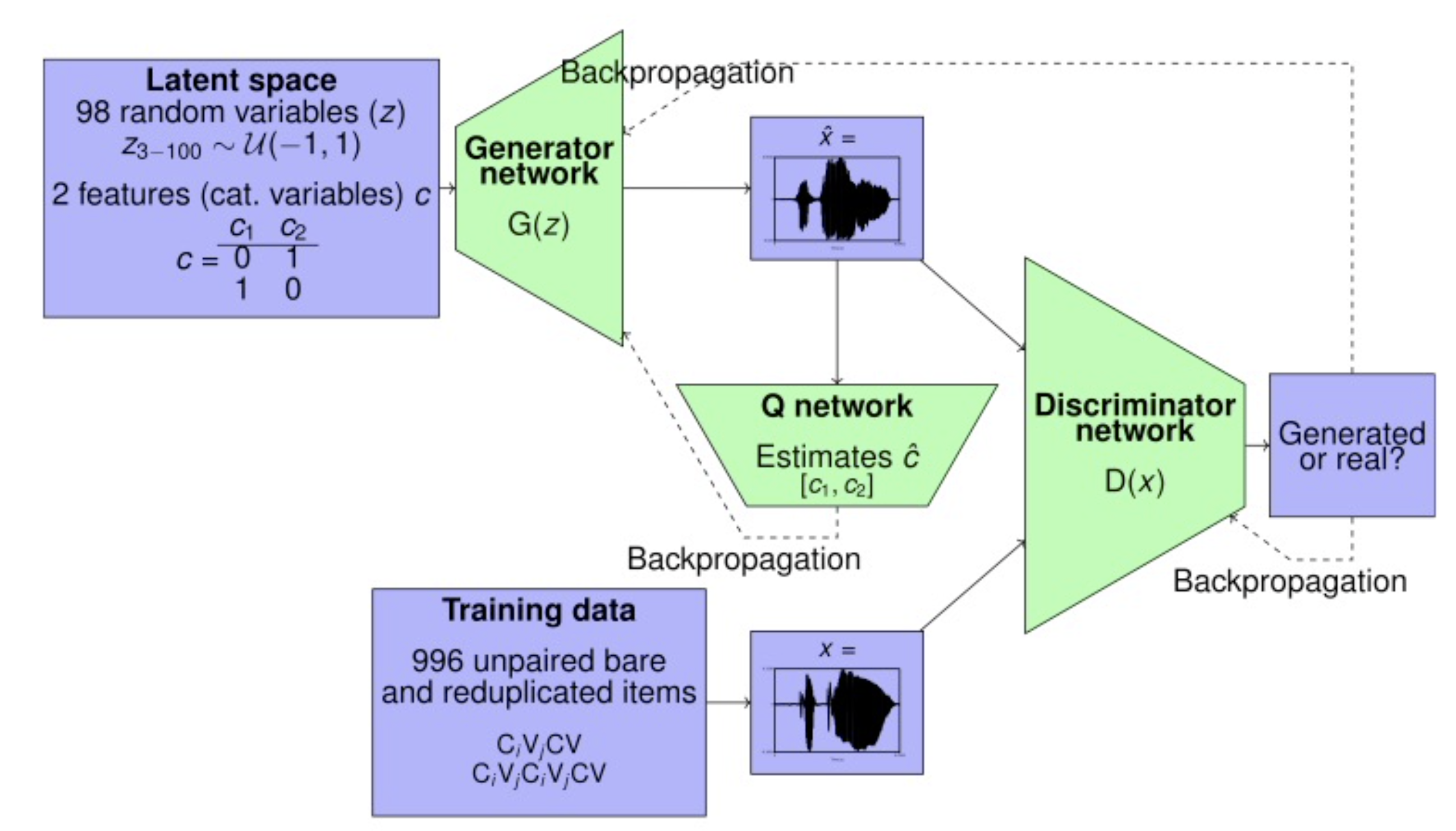
- [Aug. 2023] Paper “Exploring How Generative Adversarial Networks Learn Phonological Representations” accepted to ACL 2023 with Area Chair Awards.
Publications
-
 EACL
European Chapter of the Association for Computational Linguistics (EACL), 2026.
EACL
European Chapter of the Association for Computational Linguistics (EACL), 2026. -
 Interspeech
Interspeech, 2025.
Interspeech
Interspeech, 2025. -
 ACL
Annual Meeting of the Association for Computational Linguistics (ACL), 2023.
ACL
Annual Meeting of the Association for Computational Linguistics (ACL), 2023. -
 TTIC Workshop
TTIC Speech & Audio Foundation Models Workshop, 2025.
TTIC Workshop
TTIC Speech & Audio Foundation Models Workshop, 2025. -
 CL
Computational Linguistics, 2025.BibTeX Journal Article
CL
Computational Linguistics, 2025.BibTeX Journal Article
Services
Conference Reviewers
International Conference on Learning Representations (ICLR) 2025-2026 AAAI Conference on Artificial Intelligence (AAAI) 2025 Annual Meeting of the Association for Computational Linguistics (ACL) 2025 Annual Conference of the International Speech Communication Association (Interspeech) 2024
Blog
A collection of technical notes on speech, language, and machine learning. [View all →]
Autoregressive Models for Speech
- EnCodec: High-Fidelity Neural Audio Codec with Streaming and Variable Bitrate — Encoder/decoder architecture, RVQ, MS-STFT discriminator, loss balancer, streaming mode, ablation results.
- Codec-based TTS Pipeline: RVQ, Semantic Tokens, and Acoustic Tokens — RVQ mechanics, delay pattern, semantic vs. acoustic tokens, codebook collapse, exposure bias, EnCodec vs. DAC vs. Mimi.
Powered by Jekyll and Minimal Light theme.